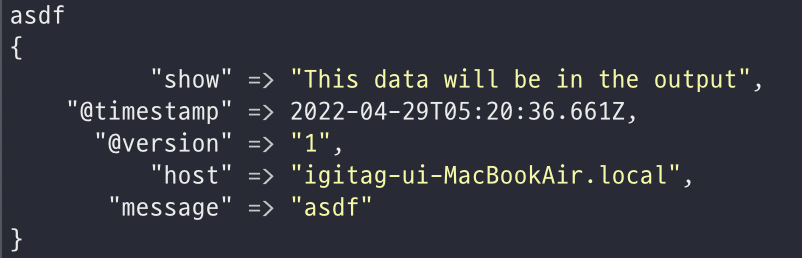
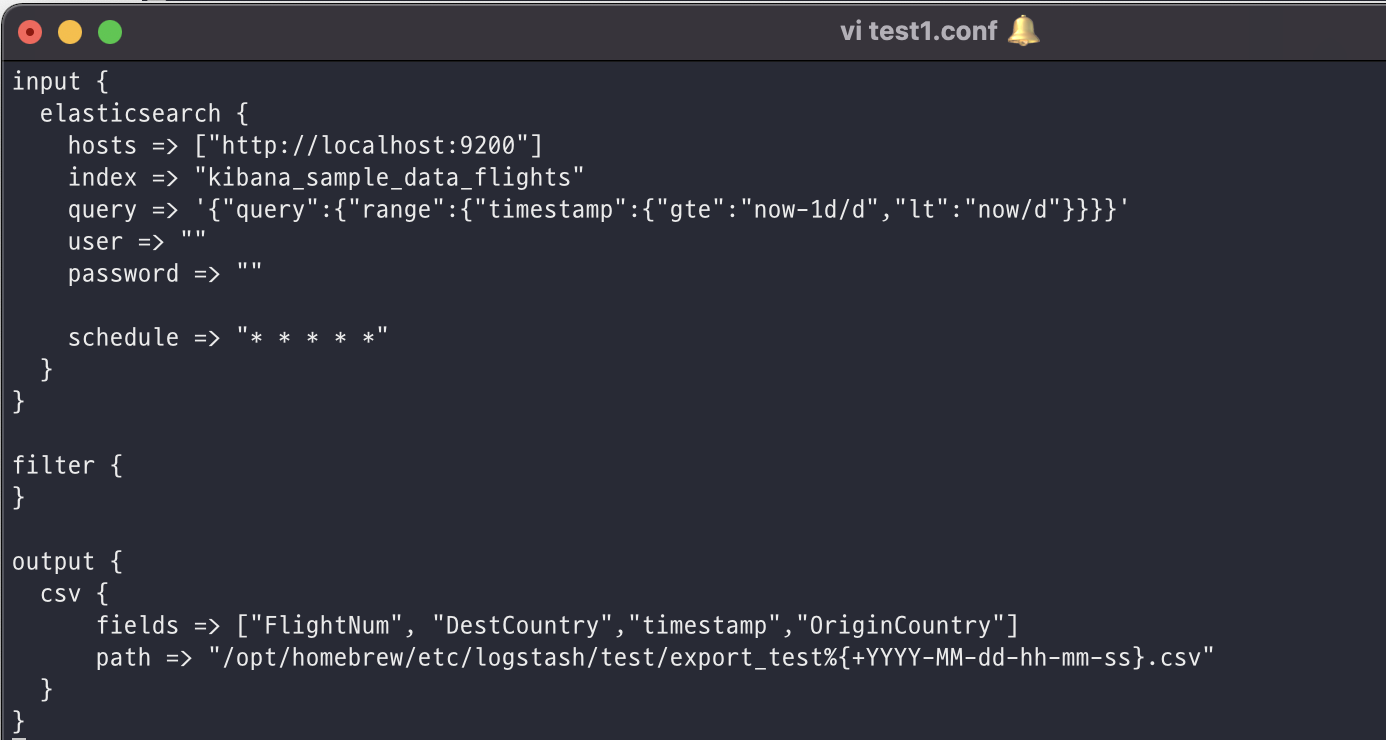
해당 포스팅 내용은 책 'Clean Code - Robert C. Martin' 출처로 합니다.
동시성과 깔끔한 코드는 양립하기 어렵다.
동시성이 필요한 이유
동시성이란? · 결합(coupling)을 없애는 전략 · 무엇(what)과 언제(when)을 분리하는 전략
무엇과언제를 분리하면 ·애플리케이션 구조와 효율이 극적으로 나아진다. -구조적인 관점에서 프로그램은 거대한 루프 하나가 아닌 작은 협력 프로그램 여럿으로 보이며, 이로 인해 시스템을 이해하기 쉬워지고 문제를 분리하기도 쉬워진다.
· 응답시간과 작업 처리량 개선에도 도움이 된다 - crawler같이 요청하고 오래 기다려야 하는 작업을 하는 경우, 여러 작업을 병렬적으로 해도 좋은 경우
동시성에 대한 오해
1. 동시성은 항상 성능을 높여준다.
동시성은 때로 성능을 높여준다. 대기 시간이 아주 길어 여러 스레드가 프로세서를 공유할 수 있거나, 여러 프로세서가 동시에 처리할 독립적인 계산이 충분히 많은 경우에만 성능이 높아진다.
2. 동시성을 구현해도 설계는 변하지 않는다.
-> 단일 스레드 시스템과 다중 스레드 시스템은 설계가 판이하게 다르다.
3.웹 또는 EJB 컨테이너를 사용하면 동시성을 이해할 필요가 없다. → 컨테이너가 어떻게 동작하는지, 어떻게 동시 수정, 데드락 등과 같은 문제를 피할 수 있는지 알아야 한다.
동시성에 대한 타당한 생각
1. 동시성은 다소 부하를 유발한다. → 성능 측면에서 부하가 걸리며, 코드도 더 짜야 한다.
2. 동시성은 복잡하다. → 간단한 문제라도 동시성은 복잡하다.
3. 일반적으로 동시성 버그는 재현하기 어렵다. → 진짜 결함으로 간주되지 않고 일회성 문제로 여겨 무시하기 쉽다.
4. 동시성을 구현하려면 근본적인 설계 전략을 재고해야 한다.
동시성을 구현하기 어려운 이유
public class X{
private int lastIdUsed;
public int getIntNextId(){
return ++lastIdUsed;
}
}
위의 코드를 살펴보자. 인스턴스 X를 생성하고, lastIdUsed 를 42로 설정한 다음, 두 스레드가 해당 인스턴스를 공유한다. 두 스레드가 getNextId();를 호출한다고 가정할 때, 결과는 셋 중 하나다.
한 스레드는 43을 받는다. 다른 스레드는 44를 받는다.lastIdUsed는 44가 된다.
한 스레드는 44을 받는다. 다른 스레드는 43을 받는다.lastIdUsed는 44가 된다.
한 스레드는 43을 받는다. 다른 스레드는 43를 받는다.lastIdUsed는 43이 된다.
객체 하나를 공유한 후 동일 필드를 수정하던 두 스레드가 서로 간섭하므로 예상치 못한 결과를 내놓는다. (두스레드가 자바 코드 한 줄을 거쳐가는 경로까지 따진다면 잠재적인 경로는 수없이 많다.)
동시성 방어 원칙
동시성 코드가 일으키는 문제로부터 시스템을 방어하는 원칙과 기술
■단일 책임 원칙(SRP)
동시성 코드는 다른 코드와 분리해야 한다.
고려할 사항
동시성 코드는 독자적인 개발, 변경, 조율 주기가 있다.
동시성 코드에는 독자적인 난관이 있다. 다른 코드에서 겪는 난관과 다르며 훨씬 어렵다.
잘못 구현한 동시성 코드는 별의별 방식으로 실패한다.
■따름 정리(자료 범위를 제한하라)
자료를 캡슐화 해야하고, 공유자료를 최대한 줄여야 한다.
공유 객체를 사용하는 코드 내임계영역(critical section)을 synchronized 키워드로 보호하라. critical section의 수를 줄이는 기술이 중요하다.
공유자료를 수정하는 위치가 많을수록
보호할 critical section을 빼먹는다. 그래서 공유 자료를 수정하는 모든 코드를 망가뜨린다.
모든 critical section을 올바로 보호했는지 확인하느라 똑같은 수고를 반복한다.
찾아내기 어려운 버그가 더욱 찾기 어려워진다.
■따름 정리(자료 사본을 사용해라)
공유 자료를 줄이려면 처음부터 공유하지 않는 방법이 제일 좋다.
객체를 복사해 읽기 전용으로 사용한다.
각 스레드가 객체를 복사해 사용한 후 한 스레드가 해당 사본에서 결과를 가져오는 방법을 사용한다.
■따름 정리(스레드는 가능한 독립적으로 구현해라)
독자적인 스레드로, 가능하면 다른 프로세서에서, 돌려도 괜찮도록 자료를 독립적인 단위로 분할하라.
각 스레드는 다른 스레드와 자료를 공유하지 않고, 클라이언트 요청 하나를 처리하도록 구현해라. 모든 정보는 비공유 출처에서 가져오며 로컬 변수에 저장한다.
라이브러리를 이해하라
■언어가 제공하는 클래스를 검토하라.
자바에서는 java.util.concurrent java.util.concurrent.atomic java.util.concurrent.locks 를 익혀라.
자바 5로 스레드 코드를 구현한다면 고려해야 할 것들
스레드 환경에 안전한 컬렉션을 사용한다. (자바 5부터 제공)
서로 무관한 작업을 수행할 때는 executer 프레임워크를 사용한다.
가능하면 스레드가 차단(blocking)되지 않는 방법을 사용한다.
일부 클래스 라이브러리는 스레드에 안전하지 못하다.
스레드 환경에 안전한 컬렉션java.util.concurrent
java.util.concurrent패키지가 제공하는 클래스는 다중 스레드 환경에서 사용해도 안전하며, 성능도 좋다. ConcurrentHashMap은 거의 모든 상황에서 HashMap보다 빠르다. 동시 읽기/쓰기를 지원하며, 자주 사용하는 복합 연산을 다중 스레드 상에서 안전하게 만든 메서드로 제공한다.
좀 더 복잡한 동시성 설계를 지원하기 위한 클래스
ReentrantLock
한 메서드에서 잠그고 다른 메서드에서 푸는 락(lock)이다.
Semaphore
전형적인 세마포어다. 개수(count)가 있는 락이다.
CountDownLatch
지정한 수만큼 이벤트가 발생하고 나서야 대기 중인 스레드를 모두 해제하는 락이다. 모든 스레드에게 동시에 공평하게 시작할 기회를 준다.
실행모델을 이해하라
기본 용어
용어
의미
한정된 자원 (Bound Resource)
다중 스레드 환경에서 사용하는 자원. 크기나 숫자가 제한적이다. ex) 데이터베이스 연결, 길이가 일정한 읽기/쓰기 버퍼
상호 배제 (Mutual Exclusion)
한 번에 한 스레드만 공유 자료나 공유 자원을 사용할 수 있는 경우를 가리킨다.
기아 (Starvation)
스레드가 오래 혹은 영원히 자원을 기다린다. ex) 짧은 스레드에게 우선순위를 준다면, 긴 스레드가 기아 상태에 빠진다.
데드락 (Deadlock)
스레드가 서로 끝나기를 기다린다. 모든 스레드가 각기 필요한 자원을 다른 스레드가 점유해 어느쪽도 진행하지 못한다.
라이브락 (Livelock)
락을 거는 단계에서 각 스레드가 서로를 방해한다. 오래 혹은 영원히 진행하지 못한다.
다중 스레드 애플리케이션에서 사용하는 실행 모델
아래의 기본 알고리즘과 각 해법을 이해하라.
1. 생산자-소비자 (Producer-Consumer)
생산자 스레드가 정보를 생성해 버퍼나 대기열에 넣고, 소비자 스레드는 대기열에서 정보를 가져와 사용한다.
스레드가 사용하는 대기열은 한정된 자원이며 생산자 스레드는 정보를 채운 다음 소비자 스레드에게, 소비자 스레드는 대기열에서 정보를 읽어들인 후 생산자 스레드에게 시그널을 보낸다.
잘못하면 생산자 스레드와 소비자 스레드가 둘 다 진행 가능함에도 불구하고 동시에 서로에게서 시그널을 기다릴 가능성이 존재한다.
2. 읽기-쓰기 (Readers-Writers)
읽기 스레드와 쓰기 스레드 중 어느 곳에 우선권을 주는 모델.
처리율을 강조하면 기아현상이 생기거나 오래된 정보가 쌓이고 갱신을 허용하면 처리율에 영향을 미친다.
간단한 전략은 읽기 스레드가 없을 때까지 갱신을 원하는 쓰기 스레드가 버퍼를 기다리는 방법. (단, 읽기 스레드가 계속 이어진다면 쓰기 스레드는 기아 상태에 빠진다.)
양쪽 균형을 잡으면서 동시 갱신 문제를 피하는 해법이 필요하다.
3. 식사하는 철학자들 (Dining Philosophers)
락을 이용하여 스레드의 접근을 제한하는 방식의 모델.
기업 애플리케이션은 여러 프로세스가 자원을 얻으려 경쟁한다.
주의해서 설계하지 않으면 데드락, 라이브락, 처리율 저하, 효율성 저하 등을 겪는다.
동기화하는 메서드 사이에 존재하는 의존성을 이해하라
■공유 객체 하나에는 메서드 하나만 사용하라.
동기화하는 메서드 사이에 의존성이 존재하면 동시성 코드에 찾아내기 어려운 버그가 생긴다. 자바 언어는 개별 메서드를 보호하는synchronized를 지원한다.
만약, 공유 객체 하나에 여러 메서드가 필요한 경우 세가지 방법을 고려한다.
클라이언트에서 잠금 클라이언트에서 첫 번째 메서드를 호출하기 전에 서버를 잠근다. 마지막 메서드를 호출할 때까지 잠금을 유지한다.
서버에서 잠금 서버에 '서버를 잠그고 모든 메서드를 호출한 후 잠금을 해제하는 메서드'를 구현한다. 클라이언트는 이 메서드를 호출한다.
연결 서버 잠금을 수행하는 중간 단계를 생성한다. '서버에서 잠금'방식과 유사하지만 원래 서버는 변경하지 않는다.
동기화하는 부분을 최대한 작게 만들어라
자바에서synchronized키워드를 사용하면 락을 설정한다. 같은 락으로 감싼 모든 코드 영역은 한 번에 한 스레드만 실행이 가능하다. 락은 스레드를 지연시키고 부하를 가중시키므로, 여기저기 synchronized문을 남발하면 안 된다.
반면,critical section은반드시보호해야 한다. 따라서 코드를 짤 때는 critical section의 수를 최대한 줄인다. critical section 개수를 줄인다고 크기를 키우면 스레드 간에 경쟁이 늘어나고 프로그램 성능이 떨어진다.
올바른 종료 코드는 구현하기 어렵다
종료 코드를 개발 초기부터 고민하고 동작하게 초기부터 구현하라. "but" 생각보다 어려우므로 이미 나온 알고리즘을 검토하라.
데드락이 가장 흔히 발생하는 문제이다.
스레드 코드 테스트하기
1. 문제를 노출하는 테스트 케이스를 작성하라.
2. 프로그램 설정과 시스템 설정과 부하를 바꿔가며 자주 돌려라.
3. 테스트가 실패하면 원인을 추적하라.(꼼꼼히 원인분석을 하는 것이 중요)
구체적인 지침
■말이 안 되는 실패는 잠정적인 스레드 문제로 취급하라.
시스템 실패를 '일회성'이라 치부하지 마라.
'일회성' 문제를 계속 무시할 경우 잘못된 코드 위에 코드가 계속 쌓인다.
■다중 스레드를 고려하지 않은 순차 코드부터 제대로 돌게 만들자.
스레드 환경 밖에서 생기는 버그와 스레드 환경에서 생기는 버그를 동시에 디버깅 하지 마라. 스레드 환경 밖에서 코드를 올바로 돌려라.
일반적인 방법의 경우, 스레드가 호출하는 POJO(순수 자바 객체)를 만들어 스레드 환경 밖에서 테스트한다.
■다중 스레드를 쓰는 코드 부분은 다양한 환경에 쉽게 끼워넣을 수 있도록 구현하라.
다양한 설정에서 실행할 목적으로 구현하라.
한 스레드로 실행하거나, 여러 스레드로 실행하거나, 실행 중 스레드 수를 바꿔본다.
스레드 코드를 실제 환경이나 테스트 환경에서 돌려본다.
테스트 코드를 빨리, 천천히, 다양한 속도로 돌려본다.
반복 테스트가 가능하도록 테스트 케이스를 작성한다.
■다중 스레드를 쓰는 코드부분을 상황에 맞춰 조절할 수 있게 작성하라.
적절한 스레드 개수를 조율하기 쉽게 코드를 구현한다. 프로그램이 돌아가는 도중에 스레드 개수를 변경하는 방법도 고려한다. 프로그램 처리율과 효율에 따라 스스로 스레드 개수를 조율하는 코드도 고민한다.
■프로세서 수보다 많은 스레드를 돌려보라.
스와핑이 잦을수록 임계영역을 빼먹은 코드나 데드락을 일으키는 코드를 찾기 쉬워진다.
■다른 플랫폼에서 돌려보라.
처음부터 그리고 자주 모든 목표 플랫폼에서 코드를 돌려라.
다중 스레드 코드는 플랫폼마다 다르게 돌아가기 때문에 코드가 돌아갈 수 있는 플랫폼 전부에서 테스트 하는 것이 마땅하다.
■코드에 보조코드(instrument)를 넣어 돌려라. 강제로 실패를 일으키게 해보라.
스레드 코드에서 간단한 테스트로는 버그가 드러나지 않는다. (수천 가지 경로 중 아주 소수만 실패하고, 실패하는 경로가 실행될 확률은 저조하기 때문)
드물게 발생하는 오류를 좀 더 자주 일으키려면, 보조 코드를 추가해 코드가 실행되는 순서를 바꿔준다. ex)Object.wait(),Object.sleep(),Object.yield(),Object.priority()
각 메서드는 스레드가 실행되는 순서에 영향을 미치기 때문에 버그가 드러날 가능성도 높아진다.
코드에 보조 코드를 추가하는 두 가지 방법
1. 직접 구현하기
코드에다 직접 wait(), sleep(), yield(), priority() 함수를 추가한다. -> 까다로운 코드를 테스트할 때 적합
2. 자동화
jiggle(흔들기) 기법을 사용해 오류를 찾아내라.
보조 코드를 자동으로 추가하려면 AOF, CGLIB, ASM 등과 같은 도구를 사용해야 한다. ex) ThreadJigglePoing.jiggle()는 무작위로 sleep이나 yield를 호출한다.
결론:
깔끔한 접근 방식을 취한다면 코드가 올바로 돌아갈 가능성이 극적으로 높아 진다.
다중 스레드 코드는 올바로 구현하기 어렵다. 그러므로 각별히 깨끗하게 코드를 짜야 한다.
SRP 준수하여야 하며 POJO를 사용해 스레드를 아는 코드와 스레드를 모르는 코드를 분리한다.
해당 포스팅 내용은 책 'Clean Code - Robert C. Martin' 출처로 합니다.
먼저 창발성이 무엇인지에 대해 알아보자
창발: 하위 계층(구성 요소)에는 없는 특성이나 행동이 상위 계층(전체 구조)에서 자발적으로 돌연히 출현하는 현상 창발성: 단순한 결합이 복잡한 결과를 나타내는 특징을 의미 - 창발적 설계란 ? -> 어떤 규칙과 원칙에 따라 설계를 하였을 때, 그것들이 모여 아주 좋은 거시적 설계가 되었을 때 이를 창발적 설계라 한다.
소프트 웨어의 설계 품질을 크게 높여주는 4가지
중요도 순
모든 테스트를 실행한다.
중복을 없앤다.
프로그래머의 의도를 표현한다.
클래스와 메서드 수를 최소로 줄인다.
위와 같은 규칙을 따를 때, 켄트벡은 설계가 '단순하다' 라고 말한다.
이러한 규칙을 잘 지킨다면,
1. 우수한 설계가 나온다.
2. 코드 구조와 설계를 파악하기가 쉬워진다.
3. SRP나 DIP와 같은 원칙을 적용하기 쉬워진다.
4. 우수한 설계의 창발성을 촉진한다.
단순한 설계 규칙1: 모든 테스트를 실행하라
설계는 시스템이 의도한 대로 돌아가는지 검증할 수 있어야 한다.
테스트가 가능한 시스템을 만들려는 노력은 낮은 결합도와 높은 응집력이라는 결과를 만든다.
테스트 케이스를 만들고 계속 실행함으로써, 설계 품질을 자연스레 높일 수 있다.
단순한 설계 규칙2: 중복을 없애라
중복이란 추가 작업, 추가 위험, 불필요한 복잡도를 뜻한다.
깔끔한 시스템을 만들기 위해서는 단 몇 줄이라도 중복을 제거하겠다는 의지가 필요하다.
동일한 코드를 새 메서드로 만듦으로써,
1. 메서드의 가시성↑
2. 재사용성 ↑ -> 시스템 복잡도 ↓
Template Method 패턴은 고차원 중복 제거할 목적으로 자주 사용된다.
Template Method 패턴: 거의 동일한 두 메소드에서 중복되는 부분을 합치고, 차이가 있는 부분만 별도의 하위 클래스에 작성하는 방법
단순한 설계 규칙3: 의도를 분명히 표현하라
엉망인 코드를 짠다면 타인 또는 미래의 나 또한 코드를 100% 이해가 힘들어진다.
개발자가 코드를 명백하게 짠다면, 다른 사람이 코드를 이해하기 쉬워지고 그 결과결함이 줄고유지보수 비용이 적게 든다.
의도를 분명히 표현하는 방법
1. 좋은 이름을 선택한다. 2. 함수와 클래스의 크기를 가능한 줄인다. 3. 표준 명칭을 사용한다. 4. 단위 테스트 케이스를 꼼꼼히 작성한다.
의도를 분명하게 표현하기 위해서는 결국노력이 가장 중요하다.
단순한 설계 규칙4: 클래스와 메서드 수를 최소로 줄여라
중복을 제거하고 의도를 명백히 표현하는 등의 기본 원칙을 극단적으로 따르면, 득보다 실이 많아질 수 있다.(비효율적이 될 가능성↑)
Elastic Stack: Elastic 회사에서 제공하는 4개의 소프트웨어로 구성된 빅데이터 파이프라인 추가적으로, X-Pack(보안, 알림, 모니터링, 머신러닝등의 기능)과 Elastic Cloud를 제공한다.
v5.0.0 이전 - ElasticSearch + Logstash + Kibana 로 이루어진 서비스 - ELK Stack 으로 불림 v5.0.0 이후 - Beats 를 시작으로 X-Pack과 Elastic Cloud 가 포함되어 Elastic Stack으로 불림
Elastic Stack의 구조
Beats: 데이터 수집 LogStash: 데이터 수집 및 집계, 전송 ElasticSearch: 데이터 저장, 색인, 분석 Kibana: 데이터 분석 및 시각화
-> Logstash나 Beats를 통해 모든 데이터를 수집하고, ElasticSearch를 통해 수집된 데이터의 검색, 처리, 저장하며 Kibana를 통해 데이터를 시각화
1. ElasticSearch
Elastic Stack의 중심
ElasticSearch란? ▶루씬(Lucene) 기반으로 개발된 분산형 오픈소스 RESTful API 검색엔진
▧ 루씬: 자바로 이루어진 정보 검색 오픈소스 SW이자 고성능 정보 검색 라이브러리
▶역할 : ◎모든 유형의 데이터(숫자, 문자열, ip, geo, date 등)를 색인하여 저장, 검색 집계를 수행 ◎이를 통해 결과를 클라이언트 및 다른 프로그램에 전달
그럼에도 왜 우리는 루씬대신 ElasticSearch를 사용할까?
루씬이 검색과 색인이 필요한 강력한 API를 제공하는 것은 맞다.
하지만, 결국 루씬은 어플리케이션이 아닌 라이브러리 ,따라서 사용자는 원하는 부분과 기능은 다 직접 개발이 필요하다.
ElasticSearch의 특징은 다음과 같다.
SchemaLess
전문검색(Full text Search)
NRT(Near Real Time)
RestFul API
클러스터식 구성
v7.x : type 구조의 삭제 v8.x: v7.x REST API 호환이 되도록 하였고, 또한 보안기능 기본적으로 활성화시킴
1.SchemaLess
여기서 SchemaLess는 스키마가 없다는 뜻이 아니라 동적으로 스키마가 생성된다는 의미이다.
DBMS는 데이터를 입력하기 전에, 테이블을 생성과 칼럼 정의 등 사전 작업이 필요하다.
하지만 ElasticSearch는 데이터를 입력하기 전에,데이터의 어떤 필드를 저장할 것인지 사전에 정의가 필요하지 않다.
왜냐하면 ElasticSearch는 자동으로 해당 데이터를 분석한 후에, 동적으로 스키마를 생성하기 때문이다.
2. 전문검색(Full text Search)
ElasticSearch는 역색인 구조를 가지고 있다.
역색인 구조를 통해 찾고자 하는 데이터가 어느 도큐먼트에 있는지 빠르게 검색 가능하다.
●Elastic Search와 RDBMS의 비교
RDBMS
ElasticSearch
schema
mapping
database
index
table
type
row
document
column
field
역색인 구조 - 1. 공백을 기준으로 text를 Tokenize
2. 토큰 별로 어느 문서에 있는지 기록
-> 검색으로 찾고자 하는 데이터가 어느 문서에 저장되어 있는지 빠르게 검색 가능
추가적으로 아래와 같은 특징들이 존재한다.
불규칙한 구조의 text도 색인 생성을 통하여 검색
다양한 데이터 타입 제공
관계형 데이터베이스에서 불가능한 비정형 데이터의 색인과 검색이 가능(빅데이터 처리에서 중요!)
텍스트를 여러 단어로 변형하거나 텍스트의 특질을 이용한 동의어나 유의어를 활용한 검색이 가능
형태소 분석을 통한 자연어 처리가 가능
3. Near Real Time(NRT)
거의 실시간으로 분석이 가능한 System이며, 색인과 검색이 거의 동시에 이루어진다.
기존의 하둡 시스템과 달리 ES cluster가 실행되는 동안에는 꾸준히 데이터가 입력(indexing) & 동시에 1초후 바로 검색 및 집계가 가능
4. RestFul API
표준 인터페이스(REST API)를 기본으로 지원,
Data에 대한 http Method를 통해 CRUD를 수행
5. Cluster 구성
대용량의 데이터 증가에 따른Scale-Out & 데이터 Integrity(무결성) 유지를 하기 위한 구성
한 클러스터 내부에 하나 이상의 노드가 존재
- cluster : 여러 대의 컴퓨터 혹은 구성 요소들을 논리적으로 결합하여 하나의 컴퓨터처럼 사용할 수 있도록 하는 기술
여러 노드를 한 클러스터 내에 생성 - 부하 분산
여러 노드 중 한 노드 장애 발생 시, 다른 노드들로 클러스터 재구성 - 안전성 확보
여러 노드에 Data Replica(복제본) 생성 - 안전성 확보
→ 운영 및 확장성 용이
ElasticSearch의 장점
유연성 & 호환성
Elasticsearch,Logstash,Kibana는 각각의 역할을 담당하기 때문에, 용도별로 분리해 version Up 및 발전하는 솔루션 - 구조적 안정성까지 보장
스키마가 자유롭다
수평 확장성
클러스터에 노드를 추가함으로써, 수평적으로 확장이 용이
부하 분산 및 안전성 확보
운영 및 확장성이 용이
사전에 준비된 다양한 부가기능
Kibana 를 통한 UI 및 다양한 부가기능 제공 - 사전의 다른 작업 요구 X
ES 버전 별 Bulk 방법 차이 완화
Bulk = (RDBMS)의 Insert
ES는 버전 별로 벌크 방법의 차이가 존재한다.
하지만 Logstash를 통하여 ES 핸들링으로 벌크 문제를 해결
ElasticSearch 단점
진입 장벽이 존재
Document 간 조인을 수행할 수 없다. (두번 쿼리로 해결해야 한다.) -> "but" ES는 애초에 조인을 할 필요가 없다.
트랜잭션 및 롤백이 제공되지 않는다.
진정한 의미의 실시간 처리가 불가능하다. (색인된 데이터는 1초 뒤에 검색이 가능하다.)
진정한 의미의 업데이트를 지원하지 않는다. (물론 있긴 하나, 삭제했다가 다시 만드는 형태)
Search Engine의 시장 현황
Elastic Stack과 Splunk 비교
공통점: Splunk와 ES의 주요 목표는 모두 시스템 로그 파일을 모니터링, 분석, 집계 및 시각화하는 것이다.
차이점: Splunk는 우수한 사용자 인터페이스를 갖춘 보다 편리한 솔루션이지만 사용자 라이선스를 구입하는 데 비용이 많이 든다. ES에 포함된 Kibana의 데이터 시각화는 초기 설정에 있어Splunk보다 덜 편리하지만 오픈 소스이기 때문에, 사용자 라이 선스 비용이 없고, ES가 Splunk에 비해 검색성능이 빠르다는 점이 강점이다.
결론: Splunk와 ELK 간의 처리 능력과 기능은 비슷하다. ELK는 구현 프로세스 초기에 설정하는 데 더 많은 작업과 계획이 필요하 지만 초기 설정 이후로는 ELK의 데이터 추출 및 시각화는 Splunk보다 사용자 친화적이고 검색 성능면에서는 월등하다.
2. Logstash
다양한 소스로부터 데이터를 수집하고 곧바로 전환하여 원하는 대상에 전송할 수 있도록 하는 경량의 오픈 소스 서버측 데이터 처리 파이프라인이다.
특징:
데이터를 수집하고 filter를 통하여 데이터를 변환(가공) 후, ES 혹은 다른 데이터 저장소로 데이터를 전달 + 비정형 데이터를 쉽게 로드
다양한 Plug-in이 지원 (유연한 플러그인 아키텍쳐)
확장 및 실시간 데이터 파이프라인 구축에 유용
Logstash의 데이터를 처리하기 위한 과정
1. Input - 입력 데이터의 다양한 형태와 크기, source등을 지원한다.
2. Filter - 데이터의 구문을 분석 및 변환 작업을 수행하며, 데이터의 형식이나 복잡성에 관계 없이 동적으로 변환한다. ex) grok filter - 비정형 데이터 구조 도출 / ip 주소 위치 좌표 해석을 하는 필터도 존재
3. Output - ES를 포함한 다양한 데이터 저장소로 사용자의 요청에 알맞는 출력 형태로 전달
3. Kibana
ElasticSearch의 데이터를 가장 쉽게 시각화할 수 있는 확장형 UI 도구
이를 통하여 사용자는
검색 및 집계 기능을 통하여 손쉽게 ES의 데이터 조작 가능
시각화 도구를 이용하여 DashBoard 및 Canvas 생성 가능
다양한 형태(json, url)로 저장 및 Export 가능
4. Beats
Logstash는 데이터 수집기로 좋긴 하나, 다양한 기능을 제공하기 때문에 상황에 따라 너무 무거울 수 있다.
-> 가볍게 데이터만 수집할 수 있는 Beats를 만들어냄
즉, Beat는 지정된 위치의 Log file 만 읽고, logstash 혹은 ES로 전달해주는 역할만 수행한다.
따라서 가공(필터)에 대한 역할을 잘 수행해지 않음(가공을 할 순 있다.)
Logstash와 Beats 비교
Logstash
풍부한 기능을 제공(filter 및 변환)
Data 가공이 필요한 경우에 사용
Beats
resource(CPU & RAM) 적게 소모
Elasticsearch로 직접 전달할 경우에 유용
별도의 분석이 필요 없는 경우
Log 자체가 json 형식이고, 가공할 필요가 없을 경우
case 1
Beat는 log 파일을 읽기만 하고 별도의 가공X
로그 파일의 format이 달라진다면?
- parsing의 역할을 하는 Logstash의 설정을 변경해주면 된다.
따라서 이러한 경우는 beat 와 logstash의 역할을 분명히 나누었다고 볼 수 있다.
-> 확장성/효율성 측면에서 좋다.
case2
beat에서 json 형태의 문서로 가공
장점 : 빠르게 ES로 로그 전송 및 수집 가능 단점 : log file format이 변경되었을 때, 모든 application 서버의 beat의 설정을 변경해야 함
+ X-Pack
Elastic Stack에 대하여 여러가지 확장 가능성을 제공
Security - 인증기능, 사용자 관리, 노드, http elasticsearch 클라이언트 간의 통신 트래픽 보호등을 하며,
field / document 수준까지 데이터를 보호 / Audit Log(감시로그) 제공
Altering - 데이터 변경사항이 있다면, 사용자에게 알림 제공
Monitoring - ELK Stack 의 상태를 지속적으로 체크하는 기능
Reporting - PDF 형식의 주기적인 보고서를 생성할 수 있습니다. 또한 email에도 전송이 가능
Graph - 데이터 시각화를 그래프로써 표현
Machine Learning - 데이터의 흐름 및 주시성 등을 자동으로 실시간 모니터링하여 문제를 식별하고 이상값 탐지등 근본 원인을 분석
+ Elastic Cloud
최신 버전의 Elasticsearch 및 Kibana를 사용하여 Amazon AWS에서 실행되는 보안 클러스터를 배포하고 관리
해당 포스팅 내용은 책 'Clean Code - Robert C. Martin' 출처로 합니다.
1. 의도를 분명히 밝혀라
좋은 이름을 지으려면 시간이 걸리지만 그로 인해 절약하는 시간이 훨씬 더 많기 때문에 좋은 이름을 짓도록 노력해야 한다.
이때, 변수나 함수 클래스 이름을 지을 때 아래와 같은 질문에 답을 할 수 있어야 한다.
▶ 변수(혹은 함수나 클래스)의 존재 이유가 무엇인가?
▶ 수행기능은 무엇인가?
▶ 사용방법은 어떻게 되는가?
만약 따로 많은 주석이 필요하다면 의도를 분명히 드러내지 못한 것이다.
->코드의 단순성보다 중요한 것은 코드의 함축성이다.
2. 그릇된 정보를 피하라
나름대로 널리 쓰이는 의미가 있는 단어를 다른 의미로 사용하면 안 된다.
예를 들어,
- hp, aix, sco는 유닉스 플랫폼이나 유닉스 변종을 가리키는 의미이다. 만약 직각삼각형의 빗변(hypotenuse)을 구현할 때 hp라는 변수 를 사용하면 독자에게 그릇된 정보를 제공할 수 있다.
- 여러 계정을 그룹으로 묶을 때, 실제 List가 아니라면, accountList라 명명하지 않는다. 프로그래머에게 List라는 단어는 특수한 의미이다.
서로 흡사한 이름을 사용하지 않도록 주의해야 한다.
유사한 개념은 유사한 표기법을 사용한다.표기된 이름은 일종의 정보이기 때문에 일관성이 떨어지는 표기법은 그릇된 정보다.
3. 의미있게 구분하라
연속된 숫자를 덧붙이거나 불용어(의미가 없는 단어)를 추가하는 방식은 적절하지 못하다.
- 연속적인 숫자를 덧붙인 이름(a1, a2, ..., aN)
- Info나 Data(의미가 불분명한 불용어)
- 변수 이름에 variable을 붙이거나 표 이름에 table을 쓰는 경우
이런 이름은 그릇된 정보를 제공하는 이름도 아니며, 아무런 정보도 제공하지 못한다.
의미가 분명히 다를 경우 접두어를 사용해도 무방하지만 어떤 변수가 존재한다고 해서 해당변수에 접두어를 붙여서 이름을 만들면 안 된다.
->읽는 사람이 차이를 알도록 이름을 지어야 한다.
4. 발음하기 쉬운 이름을 사용하라
보통 사람들은 단어에 능숙하며, 우리 두뇌의 상당 부분은 단어라는 개념만 전적으로 처리한다.
프로그래밍은 사회활동이기 때문에 다른 사람과 쉽게 소통하기 위해 발음하기 어려운 이름은 피하도록 한다.
5. 검색하기 쉬운 이름을 사용하라
문자 하나를 사용하는 이름과 상수는 텍스트 코드에서 쉽게 눈에 띄지 않는 문제점이 있다.
만약 문자 하나(혹은 상수)를 사용하는 이름에 버그가 있다면 검색으로 찾아내지 못한다.
->간단한 메서드에서 로컬변수만 한 문자를 사용한다, 이름 길이는 범위 크기에 비례해야 한다.
6. 인코딩을 피하라
이름에 인코딩할 정보는 많기 때문에 유형이나 범위 정보까지 인코딩에 넣으면 이름을 해독하기 어려운 문제점이 있다.
아래는 우리가 피해야할 이름이다.
- 헝가리식 표기법과 기타 인코딩 방식
- 멤버 변수 접두어(m_)
하지만 인코딩이 필요한 경우도 있는데 그 중 하나가 인터페이스 클래스와 구현 클래스이다.
둘 중 하나를 인코딩해야 한다면,인터페이스 클래스 이름에 접두어 'I'를 붙이는 것보다 구현 클래스 이름에 "Impl"을 붙이것이 낫다.
7. 자신의 기억력을 자랑하지 마라
독자가 코드를 읽으면서 변수 이름을 자신이 아는 이름으로 변환해야 한다면 그 변수 이름은 좋지 않은 이름이다.
이는, 일반적으로 문제 영역이나 해법 영역에서 사용하지 않는 이름을 선택했기 때문에 생기는 문제다.
전통적으로 루프에서 반복 횟수 변수는 한 글자를 사용하는 경우를 제외하고는 한 글자를 변수로 사용하는 것은 적절하지 않다.
->이름은 명료해야 한다.
클래스 이름 (혹은 객체 이름): 명사나 명사구 ( ex. Customer, WIkiPage,...)
메서드 이름: 동사나 동사구
(postPayment, deletePage,...)
(접근자, 변경자, 조건자는 javabean 표준에 따라 값 앞에 get, set, is를 붙인다.)
8. 기발한 이름은 피하라
특정 문화에서만 사용하는 농담을 이름으로 하는 것은 피하는 것이 좋다.
이는 특정 소수만 알 수 있게 된다.
- kill() 대신에 whack()을 사용하는 경우
- Abort() 대신에 eatMyShort()를 사용하는 경우
->의도를 분명하고 솔직하게 표현해야 한다.
9. 한 개념에 한 단어를 사용하라
추상적인 개념 하나에 단어 하나를 선택해 이를 고수해야 한다.
만약 추상적인 개념 하나에 단어 하나를 선택하지 않는다면 아래와 같은 문제가 생긴다.
- 똑같은 메서드를 클래스 마다 fetch, retrieve, get으로 이름을 정한 경우
- 동일 코드 기반에서 controller, manager, driver를 섞어서 쓰는 경우
->일관성 있는 어휘를 사용해야 한다.
10. 말장난을 하지 마라
한 단어를 두 가지 목적으로 사용하면 안 된다. 다른 개념에 같은 단어를 사용한다면 그것은 말장난에 불과하다.
(ex. add메서드가 기존 값 두 개를 더하거나 이어서 새로운 값을 만들 때, 집합에 같은 값 하나를 추가하는 메서드 이름을 add로 하는 경우, 이는 기존의 add 메서드와 다른 맥락이기 때문에 insert나 append라는 이름을 사용하는 것이 좋다)
->프로그래머는 코드를 최대한 이해하기 쉽게 짜야한다. (대충 훑어봐도 이해할 코드가 코드 작성의 목표)
11. 해법 영역에서 가져온 이름을 사용하라
코드를 읽을 사람도 프로그래머라는 사실을 명심해야 한다. 전산 용어, 알고리즘 이름, 패턴 이름, 수학 용어 등을 사용하는 것은 괜찮다.
하지만, 모든 이름을 문제 영역에서 가져오는 정책은 현명하지 못하다.
->기술 개념에는 기술 이름이 가장 적합한 선택이다.
12. 문제 영역에서 가져온 이름을 사용하라
적절한 '프로그래머 용어'가 없다면 문제영역에서 이름을 가져온다.
그러면 코드를 보수하는 프로그래머가 분야 전문가에게 의미를 물어 파악할 수 있게 된다.
우수한 프로그래머는 문제영역과 해법영역을 구분할 줄 알아야 한다.
->문제 영역 개념과 관련이 깊은 코드는 문제 영역에서 이름을 가져와야 한다.
13. 의미 있는 맥락을 추가하라
대다수의 이름은 스스로 의미가 분명한 이름이 없기 때문에 클래스, 함수, 이름 공간에 넣어 맥락을 부여한다.
만약 모든 방법이 실패할 경우, 마지막 수단으로 접두어를 붙인다.
(ex. firstName, lastName, street, houseNumber, city, state, zipcode라는 변수가 같이 있다면 주소와 관련이 있는 변수를 알 수 있지만, 어느 메서드가 state 변수 하나만 사용하면 변수 state가 주소 일부라는 사실을 알기 어렵다. 이때 addr이라는 접두어를 모든 변 수명에 추가한다면 맥락이 분명해진다. 하지만 더 좋은 방법은 Address라는 클래스를 생성하여 관련 변수들을 해당 클래스에 넣는 것이 다.)
14. 불필요한 맥락을 없애라
예를 들어, 고급 휘발유 충전소(Gas Station Deluxe)라는 애플리케이션을 짠다고 가정해보자.
모든 클래스 이름을 GSD로 시작한다면 IDE에서 G를 입력하고 자동완성 키를 누르면 모든 클래스가 열거된다.
이로 인해 IDE를 제대로 사용할 수 없게 된다.
하지만일반적으로 의미가 분명한 경우, 짧은 이름이 긴 이름보다 좋다.
마치면서
대부분의 사람들은 자신이 짠 클래스 이름과 메서드 이름을 모두 암기하지 못한다. 그렇기 때문에 암기는 도구에게 맡기고, 우리는 문장이나 문단처럼 읽히는 코드나 적어도 표나 자료 구조처럼 읽히는 코드를 짜는데 집중해야 한다.