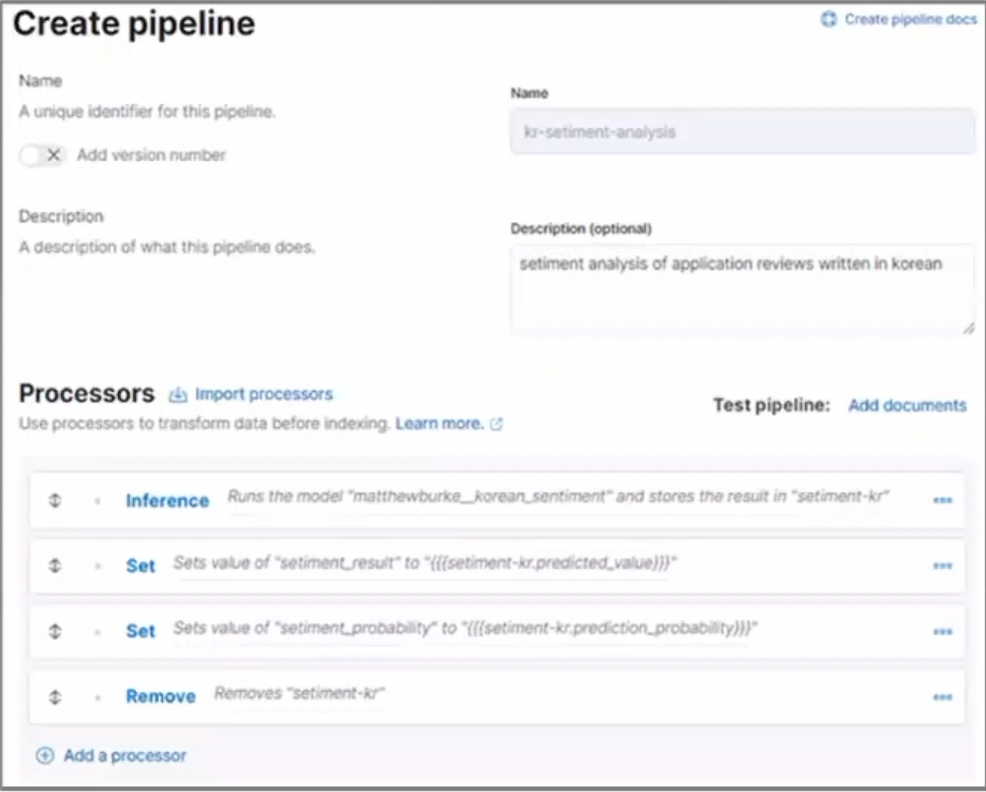
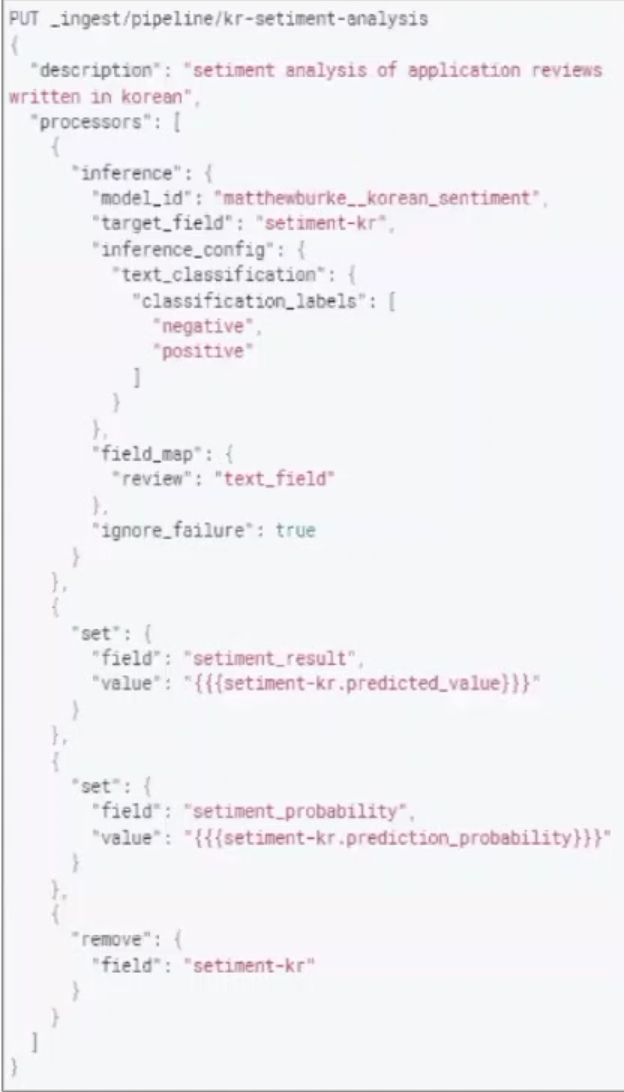
먼저 제네릭 타입에 대해 알고 넘어가자
제네릭 타입(generic type)이란?
제네릭 클래스와 제네릭 인터페이스를 통틀어 일컫는 말
클래스에서 사용할 타입을 클래스 외부에서 설정하는 것
-> class 클래스명 <타입 매개변수> { ... }
이때 타입 매개변수에는 제네릭 타입을 사용시 받아올 객체에 대한 파리미터를 대표
클래스와 인터페이스 선언에 타입 매개변수가 쓰이면, 이를 제네릭 클래스 또는 제네릭 인터페이스라 한다.
ex) List <String>의 경우
List <String>은 원소 타입이 String인 리스트를 뜻하는 매개변수화 타입인데,
String이 정규(formal) 타입 매개변수 E에 해당하는 실제(actual) 타입 매개변수이다.
또한, 제네릭 타입을 하나 정의하면 그에 딸린 로 타입(raw type)도 함께 정의된다.
로 타입(raw type)이란?
로 타입: 제네릭 타입에서 타입 매개변수를 전혀 사용하지 않을 때를 의미
ex) List <E>의 로 타입은 List이고, List <String>의 로 타입 또한 List가 된다.
로 타입을 사용하는 이유)
로 타입은 타입 선언에서 제네릭 타입 정보가 전부 지워진 것처럼 동작하는데, 제네릭이 등장하기 전 코드와 호환되도록 하기 위한 궁여지책
제네릭 도입 이전
제네릭을 도입하기 이전에는 컬렉션을 다음과 같이 선언 (자바 9에서도 여전히 동작하지만 좋은 예는 아님)
//Stamp 인스턴스만 취급한다.
private final Collection stamps = ...;
//실수로 동전을 넣는다.
stamps.add(new Coin(...)); // "unchecked call" 경고를 내뱉는다.위의 코드를 사용시 실수로 도장(Stamp)대신 동전(Coin)을 넣어도 아무 오류 없이 컴파일되고 실행된다.
로 타입을 사용했을 때의 문제
컴파일 오류를 발생시키지 않으므로 실행중에 오류(Runtime Exception)가 발생할 수 있다.
아래 코드처럼 add한 Coin 객체를 꺼내서 Stamp 변수에 할당하는 순간 ClassCastException이 발생한다.
즉, 컬렉션에서 이 동전을 다시 꺼내기 전에는 오류를 알아채지 못한다.
for(Iterator i = stamps.iterator(); i.hasNext();) {
Stamp stamp = (Stamp) i.next(); // ClassCastException을 던진다.
stamp.cancel();
}
위의 코드들의 문제점)
- ClassCastException이 발생하면 stamps에 동전을 넣은 지점을 찾기 위해 코드 전체를 훑어봐야 할 수도 있다.
- 주석( //Stamp 인스턴스만 취급한다.) 은 컴파일러가 이해하지 못하니 별 도움이 되지 못한다.
오류는 가능한 한 발생한 즉시, 이상적으로는 컴파일 할때 발견하는 것이 좋다.
제네릭 도입 이후
아래 코드와 같이 제네릭을 도입하면, Stamps 인스턴스만 취급한다는 정보가 주석이 아닌 타입 선언 자체에 녹아든다.
private final Collection<Stamp> stamps = ...;이렇게 선언하면
- 컴파일러는 stamps에는 Stamp의 인스턴스만 넣어야 함을 컴파일러가 인지한다.
- stamps에 엉뚱한 타입의 인스턴스를 넣으려 하면 컴파일 오류가 발생하며 무엇이 잘못됐는지를 정확히 알려준다.
Test.java:9: error: imcompatible types: Coin cannot be converted to Stamp
stamps.add(new Coin());
^컴파일러는 컬렉션에서 원소를 꺼내는 모든 곳에 보이지 않는 형변환을 추가하여 절대 실패하지 않음을 보장한다.
로 타입을 쓰는 걸 언어 차원에서 막아 놓지는 않았지만 절대로 써서는 안 된다.
-> 왜냐하면, 로 타입을 쓰면 제네릭이 안겨주는 안정성과 표현력을 모두 잃게 된다.
그럼에도 로 타입을 만들어 놓은 이유는 무엇일까?
로 타입을 쓰는 이유
- 호환성 문제
자바가 제네릭을 받아들이기까지 거의 10년간 제네릭 없이 짠 코드가 이미 세상을 뒤덮어 버림
↓
기존 코드를 모두 수용하면서 제네릭을 사용하는 새로운 코드와도 맞물려 돌아가게 해야 했음
↓
마이그레이션 호환성을 위해서 로 타입을 지원하고 제네릭 구현하는 소거 방식을 사용하기로 함
List 같은 로 타입은 사용해서는 안되나 List<Object> 처럼 임의 객체를 허용하는 매개변수화 타입은 괜찮다.
- List는 제네릭 타입에서 완전히 발을 뺀 것이고, List<Object>는 모든 타입을 허용한다는 의사를 컴파일러에 전달한 것
List를 받는 메서드에 List<String>은 넘길 수 있지만, List<Object>를 받는 메서드에는 넘길 수 없다.
- 제네릭의 하위 타입 규칙 때문으로 List<String>은 List의 하위 타입이지만, List<Object>의 하위 타입은 아님
- List<Object> 같은 매개변수화 타입을 사용할 때와 달리 List 같은 로 타입을 사용하면 타입 안전성을 잃게 됨
public static void main(String[] args) {
List<String> strings = new ArrayList<>();
unsafeAdd(strings, Integer.valueOf(42));
String s = strings.get(0); // 컴파일러가 자동으로 형변환 코드를 넣어준다.
}
private static void unsafeAdd(List list, OBject o) {
list.add(o);
}
위의 코드는 컴파일은 되지만 로 타입인 List를 사용하여 아래와 같은 경고가 발생
Test.java:10: warning: [unchecked] unchecked call to add(E) as a
member of the raw type List
list.add(o);
^
이 프로그램을 이대로 실행하면 strings.get(0)의 결과를 형변환하려 할 때 ClassCastException을 던진다.
(왜냐하면 Integer를 String으로 변환하려 시도했기 때문)
이 경우, 컴파일러의 경고를 무시하여 그 대가를 치른 것이다.
이제 로 타입인 List를 매개변수화 타입인 List<Object>로 바꾼다음, 다시 컴파일 해보면 오류 메시지가 발생하면서 컴파일 조차 되지 않는다.
Test.java:5: error: incompatible types: List<String> cannot be
converted to List<Object>
unsafeAdd(strings, Integer.valueOf(42));
^
한편, 원소의 타입을 몰라도 되는 로 타입을 쓰고 싶어질 수 있다.
//잘못된 예 - 모르는 타입의 원소도 받는 로 타입을 사용
static int numElementsInCommon(Set s1, Set s2) {
int result = 0;
for (Object o1 : s1)
if (s2.contains(o1))
result++;
return result;
}위의 메서드의 문제점)
메서드는 동작하지만 로 타입을 사용해 안전하지 않다.
-> 비한정적 와일드카드 타입 (unbounded wildcard type)을 대신 사용하는 것이 좋음
- 제네릭 타입을 쓰고 싶지만 실제 타입 매개변수가 무엇인지 신경 쓰고 싶지 않다면 물음표(?)를 사용할 것
- 제네릭 타입인 Set<E>의 비한정적 와일드카드 타입은 Set<?> (어떤 타입이라도 담을 수 있는 가장 범용적인 매개변수화 Set 타입)
비한정적 와일드카드 타입을 사용해 numElementsInCommon을 다시 선언
static numElementsInCommon(Set<?> s1, Set<?> s2) {...}비한정적 와일드카드 타입을 사용했을 때 장점)
- 비한정적 와일드카드 타입은 안전하지만, 로 타입은 안전하지 않음
- 로 타입 컬렉션은 아무 원소나 넣을 수 있어 타입 불변식을 훼손하기 쉽지만, Collection<?>에는 (null 외에는) 어떤 원소도 넣을 수 없다. 만약 다른 원소를 넣으려 하면 컴파일할 때 오류를 발생시킨다.(타입 불변식을 훼손하지 못하게 막는다)
//만약 다른 원소를 넣는 경우, 컴파일시 다음과 같은 오류 메시지 발생
WildCard.java.13: error: incompatible types: String cannot be
converted to CAP#1
c.add("verboten");
^
where CAP#1 is a fresh type-variable:
CAP#1 extends Object from capture of ?
이러한 제약을 받아들일 수 없다면 제네릭 메서드나 한정적 와일드카드 타입을 사용하면 된다.
와일드 카드란 무엇인가?

와일드카드: 제네릭코드에서 물음표(?)로 표기되어 있는 모든 것을 말하며, 아직 알려지지 않은 타입을 나타냄
1) 한정적 와일드카드(bounded wildcards)
● Upper Bounded wildcards (extends를 사용한 한정적 와일드카드) :
타입의 제한을 풀어줄 때 사용하며 제네릭 타입들을 상위의 제네릭 타입으로 묶어주는 것 (상위타입 이하로만 올 수 있음)
<? extends 상위타입>
ex) <? extends D> => D, E 가능
● Lower Bounded wildcards (super를 사용한 한정적 와일드카드) :
타입을 제한할 때 사용하며 유연성을 극대화하기 위해 지정된 타입의 상위 타입만 허용하는 것(하위타입 이상으로만 올 수 있음)
<? super 하위타입>
ex) <? supper D> => D, A 가능
2) 비한정적 와일드카드(unbounded wildcards)
와일드카드 문자인 ?만 사용할 때 비한정적 와일드카드라고 하며, 알려지지 않은 타입의 리스트라고 불리며 다음과 같은 상황일 때 비한정적 와일드카드를 쓴다.
1. Object 클래스에서 제공하는 메서드일 때
2. 매개변수 타입에 의존하지 않는 제네릭 클래스의 메서드를 사용할 때
ex) <?> => 모든 클래스나 인터페이스가 올 수 있다. 즉 제한없음. A ~ E 모두 올 수 있다.
List<Object>의 경우 어떤 타입도 상관없이 사용하는 것이 아니라, List의 원소로 Object타입만 받는다.
단, Object위치에는 Object의 하위타입을 넣을 수 있지만, List<?>에는 null만 넣을 수 있다.
왜냐하면 List<?>에 어떤 타입의 List가 올지 모르기 때문에 타입이 존재하는 값을 넣을 수 없기 때문이다.
로 타입을 사용하는 예외 케이스
- class 리터럴에 매개변수화 타입을 사용하지 못하게 했다. (배열과 기본 타입은 허용)
ex) List.class, String[].class, int.class는 허용하지만 List<String>.class와 List<?>.class는 허용X
- instanceof 연산자를 사용하는 경우
런타임에는 제네릭 타입 정보가 지워지므로 instanceof 연산자는 비한정적 와일드카드 타입 이외의 매개변수화 타입에는 적용할 수 없다.
로 타입이든 비한정적 와일드카드 타입이든 instanceof는 완전히 똑같이 동작한다.
비한정적 와일드카드 타입의 꺽쇠괄호와 물음표는 아무런 역할 없이 코드만 지저분하게 만드므로 로 타입을 쓰는 편이 깔끔하다.
제네릭 타입에 instanceof를 사용하는 올바른 예
if (o instanceof Set) { // 로 타입 Set<?> s = (Set<?>) o; // 와일드카드 타입 ... }
위의 코드에서, o의 타입이 Set임을 확인한 다음 와일드카드 타입인 Set<?>로 형변환해야 한다.
이는 검사 형변환(checked cast)이므로 컴파일러 경고가 뜨지X
'Effective Java' 카테고리의 다른 글
| [Effective Java] 아이템 46 - 스트림에서는 부작용 없는 함수를 사용하라 (0) | 2022.06.02 |
|---|---|
| [Effective Java] 아이템 27 - 비검사 경고(unchecked warning)를 제거하라 (0) | 2022.06.02 |
| [Effective Java] 아이템 25 - 톱레벨 클래스는 한 파일에 하나만 담아라 (0) | 2022.06.02 |
| [Effective Java] 아이템 24 - 멤버 클래스는 되도록 static으로 해라 (0) | 2022.06.02 |
| [Effective Java] 아이템 9 - try-finally 보다는 try-with-resources를 사용하라 (0) | 2022.06.02 |