자연어(Nautral Language)란?
인간이 일상에서 사용하는 언어를 의미
자연어 처리(Natural Laguage Processing): 인공지능의 한 분야로 머신러닝을 사용해 기계가 자연어를 이해하고 해석하여 처리할 수 있도록 하는 일
자연어 처리 vs 텍스트 분석
자연어 처리는 기계가 인간의 언어를 해석하는데 중점이 두어져 있다면, 텍스트 분석은 텍스트에서 의미 있는 정보를 추출하여 인사이트를 얻는데 더 중점을 둔다.
“but” 머신러닝이 보편화됨에 따라 자연어 처리와 텍스트 분석을 구분하는 경계가 없어짐
NLP가 활용되는 분야
- 텍스트 분류(Text Classification): 텍스트가 특정 분류, 카테고리에 속하는 것을 예측하는 기법을 통칭합니다. 스팸 메일 분류나 뉴스 기사의 내용을 기반으로 연애/정치/사회/문화 중 어떤 카테고리에 속하는지 자동으로 분류해주는 프로그램이 이에 속합니다. 텍스트 분류는 지도학습입니다.
- 감성 분석(Sentiment Analysis): 텍스트에 나타나는 감정/기분 등의 주관적 요소를 분석하는 기법을 통칭합니다. SNS의 글을 분석하여 글쓴이의 감정을 분석하는 것, 영화 및 제품의 리뷰를 분석하는 것 등이 이에 속합니다. 지도학습 뿐만 아니라 비지도학습을 이용할 수도 있습니다.
- 텍스트 요약(Summarization): 텍스트에서 중요한 주제를 추출하여 요약하는 기법을 의미합니다. 토픽 모델링(Topic Modeling)이 이에 속합니다.
- 텍스트 군집화(Clustering)와 유사도 측정: 비슷한 유형의 텍스트에 대해 군집화하는 기법을 뜻합니다.
- 기계 번역(Translation): 구글 번역기나 파파고와 같은 번역기에도 활용됩니다.
- 대화 시스템 및 자동 질의 응답 시스템: 애플의 시리나 삼성 갤럭시의 빅스비, 챗봇 등이 이에 속합니다.
NLP 처리 프로세스
1. 텍스트 전처리(Text Preprocessing): 대/소문자 변경, 특수문자 삭제, 이모티콘 삭제 등의 전처리 작업, 단어(Word) 토큰화 작업, 불용어(Stop word) 제거 작업, 어근 추출(Stemming/Lemmatization) 등의 텍스트 정규화 작업을 수행하는 것이 텍스트 전처리 단계에 속합니다.
2. 피처 벡터화 (Feature Vectorization): 전처리된 텍스트에서 피처를 추출하고 여기에 벡터 값을 할당합니다. 대표적인 피처 벡터화 기법은 BOW(Bag of words)와 Word2Vec이 있습니다.
3. 머신러닝 모델링: 피처 벡터화된 데이터에 대하여 모델을 수립하고 학습/예측을 하는 단계입니다.
Elastic Stack 8.0 릴리즈부터 Pytorch를 이용해 NLP를 처리하는 것이 가능해졌다.
BERT(구글에서 개발한 NLP 사전 훈련 기술)와 비슷한 모델을 사용하기 위해 Elasticsearch는 PyTorch 모델 지원으로 가장 일반적인 NLP 작업의 대부분을 지원한다.
NLP 작업의 예시
- 감정 분석
- : 긍정적인 진술과 부정적인 진술을 식별하기 위한 이진 분류
- NER(Named Entity Recognition)
- : 구조화되지 않은 텍스트에서 구조를 구축하고 이름, 위치 또는 조직과 같은 세부 정보를 추출하려고 시도합니다.
- 텍스트 분류
- : Zero-shot 분류를 사용하면 사전 교육 없이 선택한 클래스를 기반으로 텍스트를 분류할 수 있습니다.
- 텍스트 임베딩
- : k-nearest neighbor (kNN) search에 사용된다. (머신러닝에서 사용되는 분류(Classification) 알고리즘으로, 유사한 특성을 가진 데이터는 유사한 범주에 속하는 경향이 있다는 가정하에 사용)
Elasticsearch의 NLP
Elastic 8.0 이후, 사용자는 Elasticsearch에서 직접 PyTorch 머신 러닝 모델(BERT 등)을 사용하거나, Hugging Face와 같은 리포지토리에 있는 커뮤니티에 게시된 모델을 사용할 수 있습니다.
사용자가 Elasticsearch 내에서 직접 추론을 수행할 수 있게 됨에 따라
- (코딩 없이) **최신 NLP의 강력한 기능을 검색 애플리케이션과 경험에 통합**하는 것이 그 어느 때보다 쉬워지고,
- (Elasticsearch의 분산 컴퓨팅 성능 덕분에) 본질적으로 더 효율적이며,
- 데이터를 별도의 프로세스나 시스템으로 이동할 필요가 없어 NLP 자체가 현저하게 더 빨라집니다.
PyTorch 모델을 업로드하기 위한 Eland 클라이언트 와 Elasticsearch 클러스터에서 모델을 관리하기 위한 Kibana의 ML 모델 관리 사용자 인터페이스를 사용 하여 사용자는 다양한 모델을 시험해보고 데이터에서 수행하는 방식에 대해 좋은 접근을 할 수 있습니다. 또한 클러스터의 여러 사용 가능한 노드에서 확장 가능하고 우수한 추론 처리량 성능을 제공받기를 원하는데, 이 모든 것을 가능하게 하려면 추론을 수행할 기계 학습 라이브러리가 필요합니다.
Elasticsearch에서 PyTorch에 대한 지원을 추가하려면 PyTorch를 지원하는 기본 라이브러리 libtorch를 사용해야 하며, TorchScript 표현으로 내보내거나 저장된 PyTorch 모델만 지원합니다.
Elasticsearch는 다양한 NLP 작업 및 사용 사례에서 작동하는 플랫폼을 제공할 수 있습니다.
PyTorch NLP, Hugging Face Transformers 또는 Facebook의 Fairseq와 같은 라이브러리를 사용하여 모델을 Elasticsearch로 가져와 해당 모델에 대한 추론을 수행할 수 있습니다. Elasticsearch 추론은 처음에는 수집 시에만 이루어지며 향후에는 쿼리 시에도 추론을 도입할 수 있도록 확장할 수 있습니다.
Elasticsearch에서 데이터를 스트리밍하기 위한 API 호출 및 플러그인 및 기타 옵션을 통해 NLP 모델을 통합하는 방법이 8.0 이전에도 있었습니다.그러나 8.0이후 Elasticsearch 데이터 파이프라인 내에서 NLP 모델을 통합하면 다음과 같은 이점을 얻을 수 있습니다.
- NLP 모델을 중심으로 더 나은 인프라 구축
- NLP 모델 추론 확장
- 데이터 보안 및 개인 정보 보호 유지
Elasticsearch가 주관한 2022 0525 NLP Webinar 내용
개요:
- 구글 플레이에서 앱의 리뷰(사용자ID, 별점,날짜, 리뷰내용, 좋아요등)를 크롤링한다.
- 구글 번역기를 통해 리뷰를 영문번역 후 각각 한글감성모델과 영어감성모델을 적용후 둘을 비교한다.
Elastic search에서 NLP를 사용하기 위한 과정
👉
1. Select a trained model
2. import the trained model and vocabulary
3. Deploy the model in elasticsearch cluster
4. try it out
1. Select a trained model
- HuggingFace에서 Models 선택

- 검색창에 korean_sentiment 입력 후, 아래의 모델 선택

2. import the trained model and vocabulary
elasticsearch는 python 라이브러리로 학습된 모델만 적용이 가능 → pytorch로 학습된 모델을 사용 +
가져온 모델을 elasticsearch로 import
eland 관련 공식 document: https://www.elastic.co/guide/en/elasticsearch/client/eland/current/overview.html
eland version별 차이
8.1 - config.json이 생성됨, config.json을 통해서 수정가능
8.2 - config.json을 생성하지 않음, NlpTrainedModelConfig 객체 사용가능, NlpTrainedModelConfig의 세부내용을 customize가능
1. PyTorch 추가 종속성과 함께 Eland Python 클라이언트를 설치합니다 .

2. eland_import_hub_model 스크립트를 실행합니다 . 방식은 아래와 같습니다.


자세한 내용은 해당 참조: https://github.com/elastic/eland#nlp-with-pytorch

3. Deploy the model in elasticsearch cluster
kibana실행 → machine learning 누르기 → trained models 누르기→ start deployment
이때, 모델중에 용랑이 큰것들이 있으므로 인스턴스는 4GB이상으로 설정하는 것이 좋음
- kibana접속 후, 실행하는 방법은 아래와 같다.

4. try it out
index 설정 → add NLP inference to ingest pipeline
NER(name entity recognition)- 텍스트를 분석해 사람인지 장소인지를 구분하여 추출
text classification - 긍정,부정을 구분
hugging face사이트에서 model 설정(korean-sentiment모델을 사용)
- Pipeline을 만드는 방법은 2가지가 있으나 첫번째 방법이 더 쉽다.
1. Kibana → Stack Management → Ingest Pipelines → Create pipeline
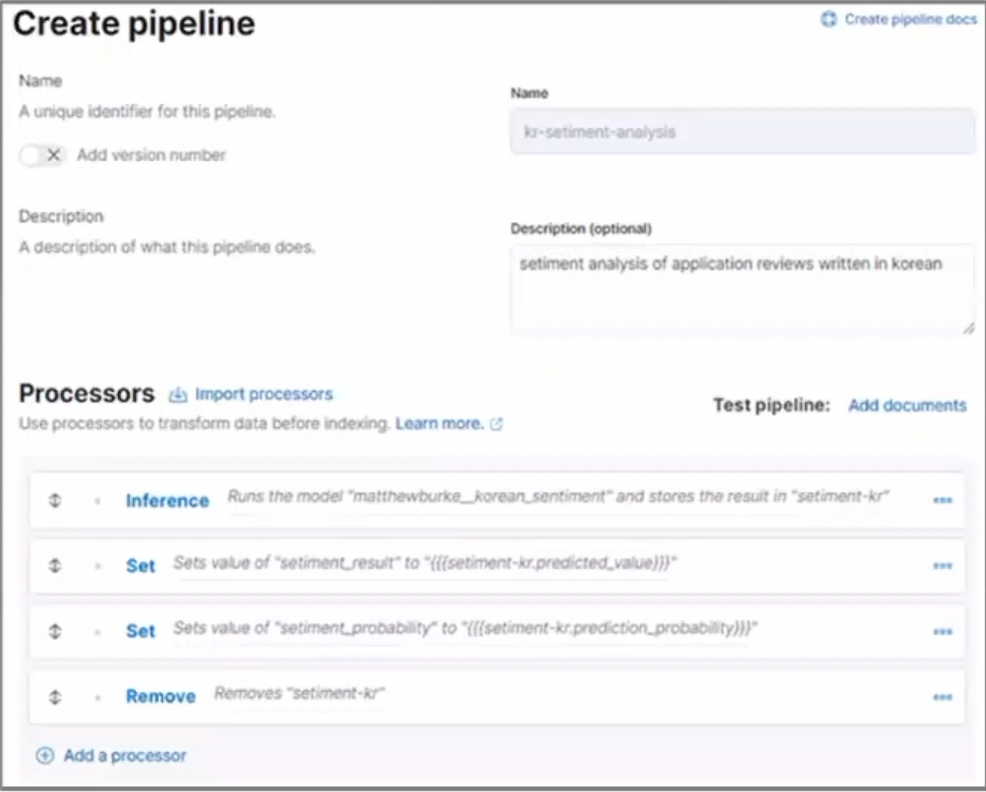
2. Kibana → Dev tools → Create pipeline
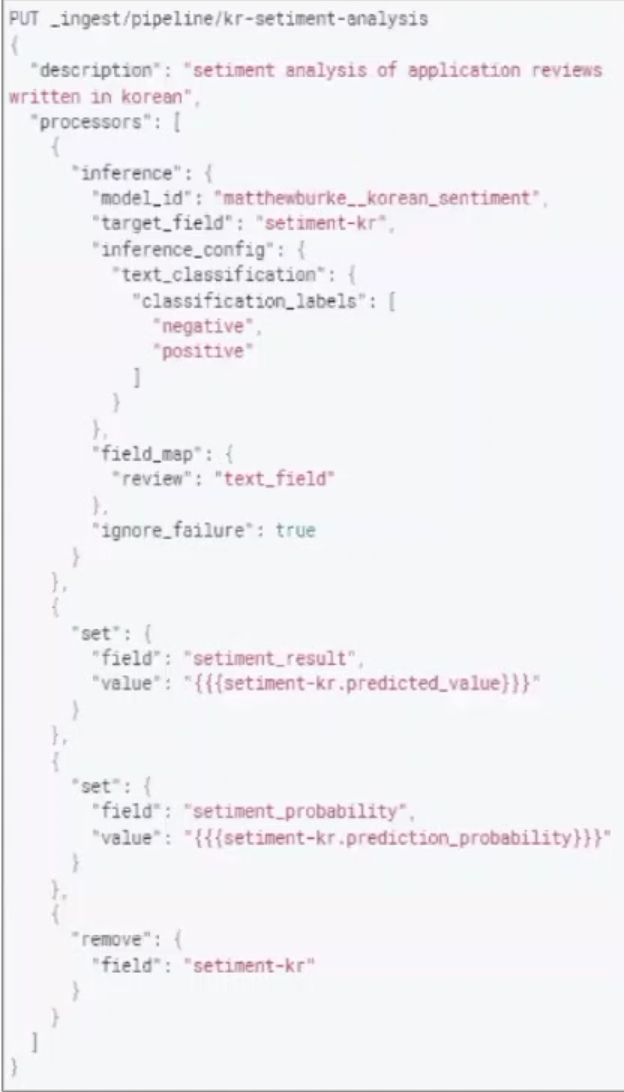
분석결과
- 각자언어에 대한 정확도는 80%이상이라고 판단
- 이때 한글감성 모델과 영어감성 모델의 차이는 해석을 어떻게 하느냐에 따라 같은 리뷰도 긍정,부정이 다르게 나올 수 있음
위 내용은 Elasticsearch에서 주관한 Webinar를 참고하였습니다.
참고: https://bkshin.tistory.com/entry/NLP-1-자연어-처리Natural-Language-Processing란-무엇인가
https://www.elastic.co/blog/introduction-to-nlp-with-pytorch-models
https://www.elastic.co/kr/blog/whats-new-elastic-8-0-0
'ElasticSearch' 카테고리의 다른 글
| 조건문 사용(If Else 문) (0) | 2022.04.29 |
|---|---|
| 매일 ES에 있는 data를 CSV파일로 만들기 (0) | 2022.04.26 |
| ElasticStack에 대해 (0) | 2022.03.15 |